Web servers communicate with browsers or other clients using the Hypertext Transfer Protocol (HTTP), which is a simple protocol that standardises the way requests are sent and processed. This allows a variety of clients to communicate with any vendor's server without compatibility problems. Hypertext allows a user to refer to other documents stored in the same computer or in a computer located in a different part of the world. It allows information to be almost tridimensional. Not only can read sequentially, but can jump for more elsewhere.
Some of the most important features include the following:
We can customise the error responses with the use of files or scripts. The server will intercept an error and display the specified file or execute a CGI that could perform an on-the-fly diagnosis of the problem. This allows our server to return more meaningful error messages to visitors or to perform some special action in response to an error condition. Apache servers can automatically negotiate content retrieval with a browser and can serve the most appropriate out of various sets of equivalent documents. This allows the server to retrieve the document having the best representation that the client is willing to accept. For example, when serving documents in English and Spanish, depending on the browser settings, Apache will automatically retrieve the version most appropriate. Apache provides several user authentication methods ranging from flat-file user databases, to indexed files and relational database support.
Configuring Apache is very easy to do. Apache utilises three configuration files; all of which are already preset to safe default behaviours. We just need to specify a few file locations, and name our server so that Apache can find its configuration files and the location of the document tree it is serving. To do this, all we need is a good UNIX text editor that we feel comfortable with.
Students, teachers, librarians, employees, scientists, lecturers, researchers, managers, singers, musicians, CD collectors, music gropes and readers are all among intended users. Libraries, Government organisations, entertainment companies, universities, musical shops and other on-line books/CD site maintainers are all among the audience who may find this product useful.
Eg: From the Information page a user can access to the privacy policy, in that window there are two navigation functions to go to the main page (Internet Books Archive home page) and to the previous page (Information page).
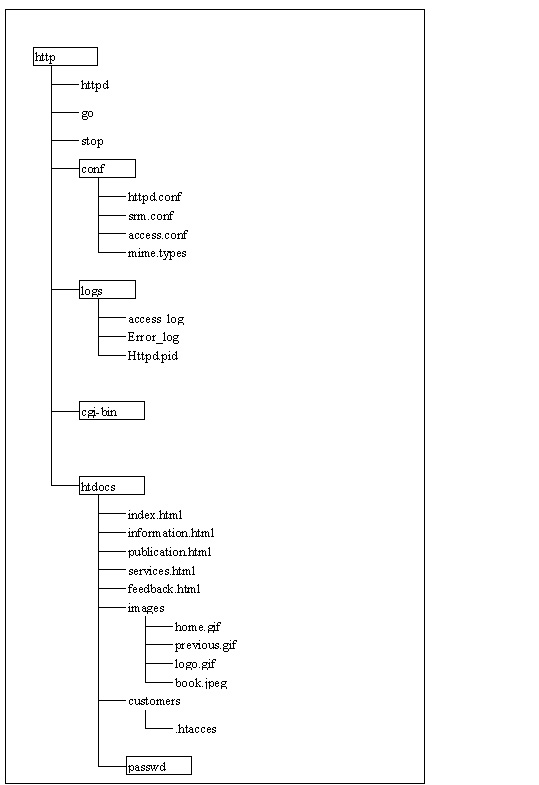
httpd.conf file
httpd.conf contains the main server configuration information. The basic behaviour of the server is contained in this file, such as how it runs, UIDs it runs under, what port it listens to, performance issues, and information on how to find other configuration files.
srm.conf file
srm.conf is the server's resource configuration file. The directives in this configuration file define the namespace that users can access on our server and the settings that affect how requests are serviced and formatted. The directives in this file control the location of the various resources that the server will access to retrieve information, such as DocumentRoot, the path to other employees home pages (if necessary and if there’s any), the location of the cgi-bin directory, the file the server looks for when the URL ends in a directory, the icons and format the server uses for displaying automatic directory listings, and so on. Directives in this file also map other areas of our UNIX file system into the server's document tree. This allows us to store resources, such as our cgi-bin directory, and make them available as if they were located within the directory specified by DocumentRoot.
access.conf file
access.conf is the server's global access-configuration file. This file defines the types of services that are allowed and under what circumstances. Careful configuration of this file is important because many security issues can be avoided if we do our configuration correctly. access.conf defines whether the server will handle server-side includes, execute CGI programs, follow symbolic links, or generate automatic indexes of directories when an index.html file is not found. Many aspects can be overridden by allowing use of per-directory access files (.htaccess files); however, this has a very adverse consequence on the performance of the server. If we can manage it, it is much better to handle all access-configuration issues in the global access-configuration file.
mime.types file
The mime.types file more than likely won't ever need configuration from us. This file maps MIME formats to file types that the server uses to know which files comply with which MIME standard. This file provides the crucial mapping that allows our server to understand the content of a file from its extension.
Other directives is a broad category that includes everything else that is not part of the core. These directives enhance the server. Many of them are actually included in the default server configuration (also called the base) because they are incredibly useful. Directives that are part of the base build, are available for use without the need to re-compile the server. In addition to core and other directives, there are many other directives provided by optional modules. We can call these specialised directives because they add specialised functionality that not all servers will need.
It's no miracle that this basic structure also happens to follow the physical structure of the site. The directory structure mirrors the navigational structure, providing another level of reinforcing the way the site is organised for people who update and manage this site. Just by navigating it, we have an understanding of the physical layout of a site. If we are using one general graphics directory, each graphic would need a unique name or some other cryptic-naming scheme. By localising resources near their point of use, each name is descriptive, clear, and readable. This also removes a lot of the creativity involved in inventing filenames. The context of the file provides information about what it is, so we don't need to peek into the file to figure out what it contains. When you are creative with your filenames, it becomes more difficult to know what a file contains. For an instance what is header2.gif? we don't know because there's no context, and doubt that the person who created such a file could remember either. If it's all packaged, then we know who's the client of that resource, and we can create a visual and organisational association; that we know what things are.
We better title everything firstSecondThird.type. The first word is in lowercase letters. Any word after has its first letter in uppercase. We are not going to use spaces, dashes, or any other character that is not a letter or a number. Periods are used to separate file extensions. This makes it easy for us to read and type filenames, and it removes the possibility of any non-alphanumeric characters from becoming part of a filename.
We should be able to tell that Apache, from a software standpoint, is fairly secure. No known bugs have severe security implications in the current version, and if one was discovered, the Apache team would be quick to rectify the situation. Always run the latest and greatest software to avoid problems. From a Web server standpoint, the main focus of our worries should focus on CGI and SSI because these two powerful features usually process user data.
If we want to execute a CGI program, we need to run a Web server like Apache because CGI transactions cannot be simulated by the browser. CGI calls happen only on the server side. On execution, most CGI programs will
At its most basic level, a CGI program will usually collect information from an HTML form, process data in the form, and then perform some action such as e-mailing data to a person. In its most complex form, there are virtually no limits to what can be done with a CGI program. CGI programs can interact with databases by fetching and storing various pieces of information to produce some sort of result.
Because of the stateless nature of the World Wide Web, there is no way to track a user from page to page using just conventional document-serving techniques. CGI allows communication, through a standard set of environment variables, between the HTTP server and a program running on the server computer - in this case, a CGI program. All sorts of things are possible with CGI that were not feasible with just HTML.
The problem with CGIs and other executable processes is that they are programs. Security problems are usually introduced by bugs in programs. While our Web server is fairly secure, programs that we implement may not take into account some of the treachery that some people will go through to break into our site. With that said, realise that someone may be able to exploit a weakness on a CGI program that we create.
To enable CGI, we will need to uncomment the ScriptAlias directive in our conf/srm.conf file and restart the server. The ScriptAlias directive specifies a directory where the server can execute programs. This provides a restrictive setup because the server will only execute programs that are found in this directory.
Because the server restricts the execution of CGI to designated directories, the organisational structure previously presented would require that all CGIs live in a central location. To enable CGI in predetermined directories, all we need to do is set an option that enables the execution of CGIs on a properly named directory. We can accomplish this with a
(Directory *.ws/local-cgi)
AllowOverride None
Options ExecCGI
(/Directory)
Security and Permissions
Exercising security on our Web site means enforcing policies. If we happen to allow per-directory access files, in a way we have relinquished some control over the implementation of that policy. From an administrative point of view, it is much better to manage one global access file (conf/access.conf) with many different entries than a minimal global configuration file plus hundreds of per-directory access files. Per-directory access files also have the terrible side effect of slowing down our server considerably because, once enabled, our server will scan each directory in the path to a request. If found, it then needs to figure out what options to apply and in what order. This takes time.
The Options Directive
Permissions are specified in Access Control
Apache provides us with several methods of authenticating users before we grant them access to our materials. Third-party modules provide support for an even greater number. We can authenticate using cookies, SQL databases, flat files, and so on. We can also control access to our machine based on the IP of the host requesting the documents. Neither of these methods provides a good measure of security by themselves; however, together they are much more robust.
There are a few issues that should be mentioned before we rely on any of these methods.
Filtering By Address
Although looking at a machine's address to determine if it is a friendly computer is better than not doing it, any host can be spoofed. Some evildoers on the Net can configure their computers to pretend to be someone we know. Usually this is done by making a real host unavailable and then making the Domain Name System (DNS) provide the wrong information. For our security, we may want to enable -DMAXIMUM_DNS while compiling the server software (under Apache there's a new directive HostnameLookups that does the same thing as a runtime directive). This will solicit a little more work on our computer because DNS information will need to be verified more closely. Typically, the server will do a reverse lookup on the IP address of a client to get its name. Setting up the HostnameLookups will force one more test. After the name is received, the server will query DNS for its IP address. If they both match, things are cool. Otherwise, the access fails.
Login and Passwords
One problem with login and password verification over the Web is that an evildoer can have a ball at trying to crack a password. On many UNIX systems, if we tried this at a user account, the system would eventually disable access to the account, making it more difficult to break in. On the Web, we could try a few hundred passwords in a few seconds (with a little software) without anyone noticing it. Obviously, this doesn't present much danger, with the exception of obtaining access to private information, until we consider that most users use one password for most services.
In our directory structure we use a restricted file under htdocs /customers call .htaccess and this file is only accessed by our systems Administrator because this is the file contains all the information about our customers, such as their names, credit card details and contact information as well as their interests. We store all the passwards and login ids in a separate derective under http call passwd.
Basic Authentication
Basic authentication is basic in that information exchanged between the browser and the server is not encrypted in any way. This method only encodes, not encrypts, the authentication session. Anyone that can intercept our authentication session can decode it and use the information to access our materials. The browser sends in authentication information with each request to the protected realm, which means that our login and password are sent not once, but several times through the wire.
To resolve this problem, a new method has been introduced: Digest authentication. Unlike Basic, Digest encodes and encrypts (trivially) the password in a way that it is only valid for the requested resource. If someone captured the authentication information and was able to decode it, that password would only be useful to retrieve that one resource. Access to each page requires a new password, which the browser generates. This makes the entire process a bit more secure.
Backing up the system
The most important issue is backing up our system. If our system catastrophically failed, how long would it take us to get it up and running again? If it took us weeks to set up and install everything the first time, doing it over is not acceptable and definitely not fun. Instead, do it once and back it up. In case of a failure, replace the hardware or software that caused the failure with our backups
If our information system is critical to our organisation, any down-time is unacceptable. This means that we must build redundant systems that guarantee the trouble-free, continuous operation of our site. How much we can do depends on your budget. So I recommend to use write-once CD ROMs as backup media. CDs created by write-once CD-ROMs are not as rugged as pressed CDs, but will last forever if we take care of the disk. These disks are compatible with any desktop system that has a CD-ROM, which has helped in making this a popular Write Once Read Many (WORM) format. Current capacity is about 600MB. Recording speed is slow. New formats for CD-ROMs that are currently in the works will yield 17GB storage, making it a very interesting solution to backup and archival tasks. Backing up is not hard to do, and it is an essential task as well.
Content and Design
Web Site Documentation
Images
There are quite a number of images using in this site. Each of them are not more than 10Kbytes and we use
Location
All images are located (stored) in a file call images under htdocs directive.
Text
We use standard size - 12 font for the text information and headers are vary from H1 to H3, and also use bold and italic facilities to highlight some important information.
Navigation symbols
We use two images to link previous page and the main page (Internet Books Archive’s home page). Use the same images in every page.
For the use of some users we include a frame free version of our site in case their browsers can not display frames.
Publication policy
Internet Books Archive’s goal is to keep you informed of special offers and products that match your interests and enhance your life, and to provide excellent service to you, our customers and business partners, while building a long lasting relationship with you. So, your participation in any offer, survey, or contest is completely optional.
Our Web server does not automatically recognise information regarding the domain or e-mail address of each customer. When you visit Internet Books Archive, you may be providing information to us on two different levels about your visit:
We want you to be aware of how we handle this information. As you browse the site, Internet Books Archive’s computers collect information about your visit, not about you personally. Via web server logs and browser cookie files, we monitor statistics such as:
How many people visit our site
Which pages people visit on our site
From which domains our visitors come (e.g., "gte.net" or "aol.com")
Which browsers people use to visit our site
While we gather this information, none of it is associated with you as an individual. We use these statistics to improve our Web site, to monitor its performance, and to make it easier for you and other visitors to use. Personal information you knowingly give us are the information you may be asked to give us, such as when you ask a question that requires a response, request rate information online and order information. Therefore, when you order an item from Internet Books Archive, we collect your name, address, phone number, e-mail address and responses to specific questions regarding the item(s) ordered. In addition, we also store the responses you give in any questionnaires or surveys offered by Internet Books Archive. Then we use your information to fulfil your order.
The information we collect from you is used by Internet Books Archive in the following ways:
If you wish to be removed from Internet Books Archive’s active database, please submit your request using our contact details. Rest assured, if you elect to be removed from our database, your information will not be used by Internet Books Archive, or sold, rented or distributed to a third party from the date you make your request. If you choose to remain on our database, you will receive exclusive information on free offers, contests, gift suggetions and more.
By using our website, you consent to the collection and use of this information by Internet Books Archive. If we decide to change our privacy policy, we will post those changes on this page so that you are always aware of what information we collect, how we use it, and under what circumstances we disclose it. Internet Books Archive respects your privacy and uses the information we have about you with integrity and full disclosure. If you ever feel this promise has been broken, let us know. If you have any additional questions or comments, please contact us at:
Internet Books Archive
P O Box U 319,
CSU - R, Wagga Wagga,
Australia.
e-mail: Kanchibenji@hotmail.com
Liability and Copyright
References
{kind=link}
{kind=link}
{kind=link}